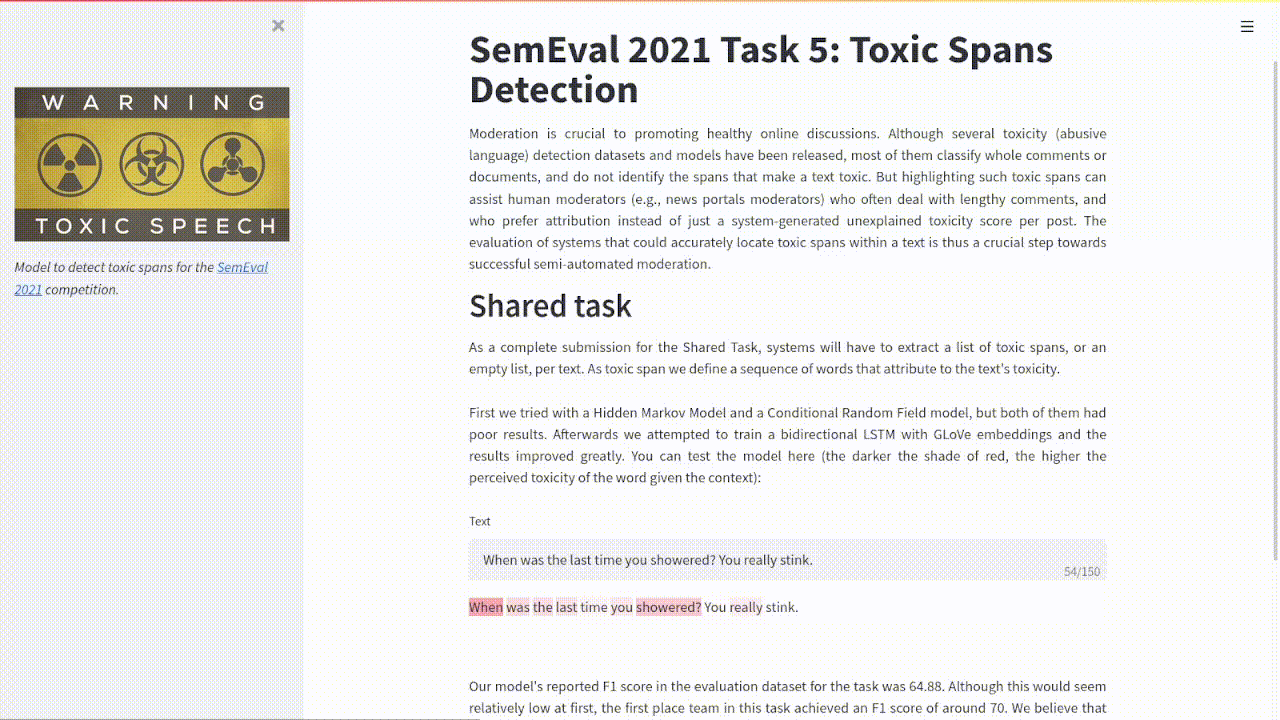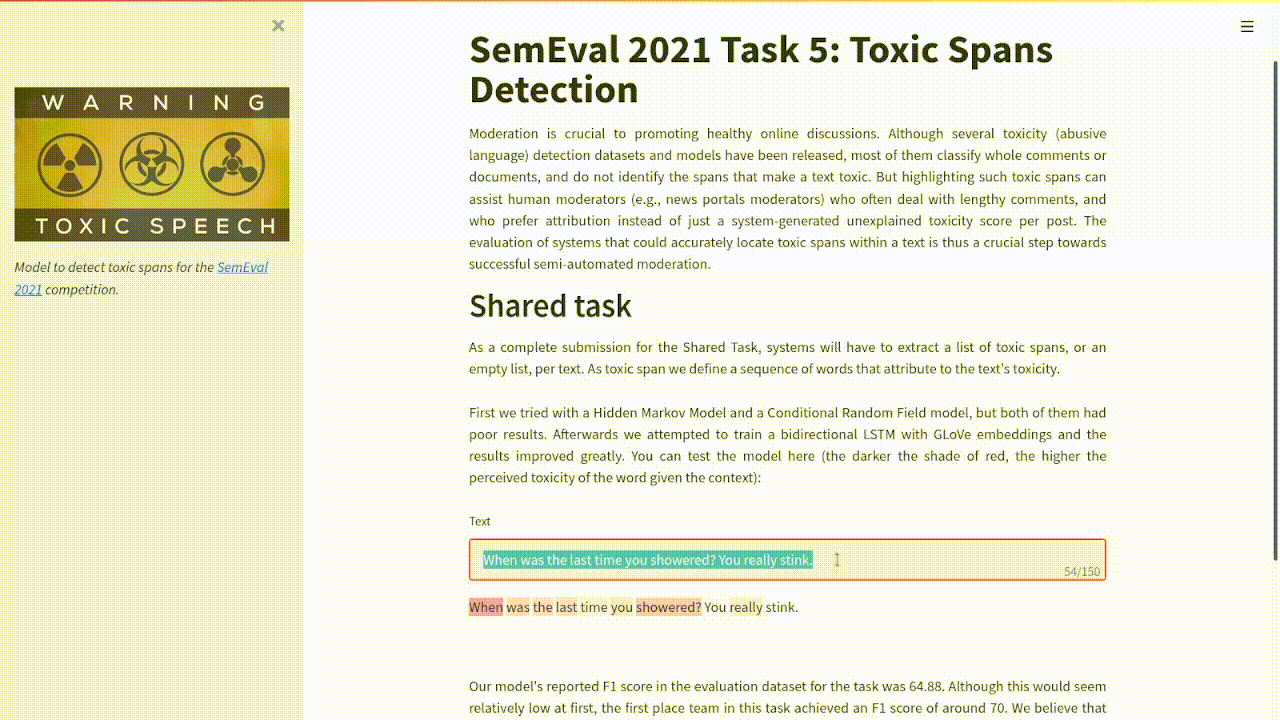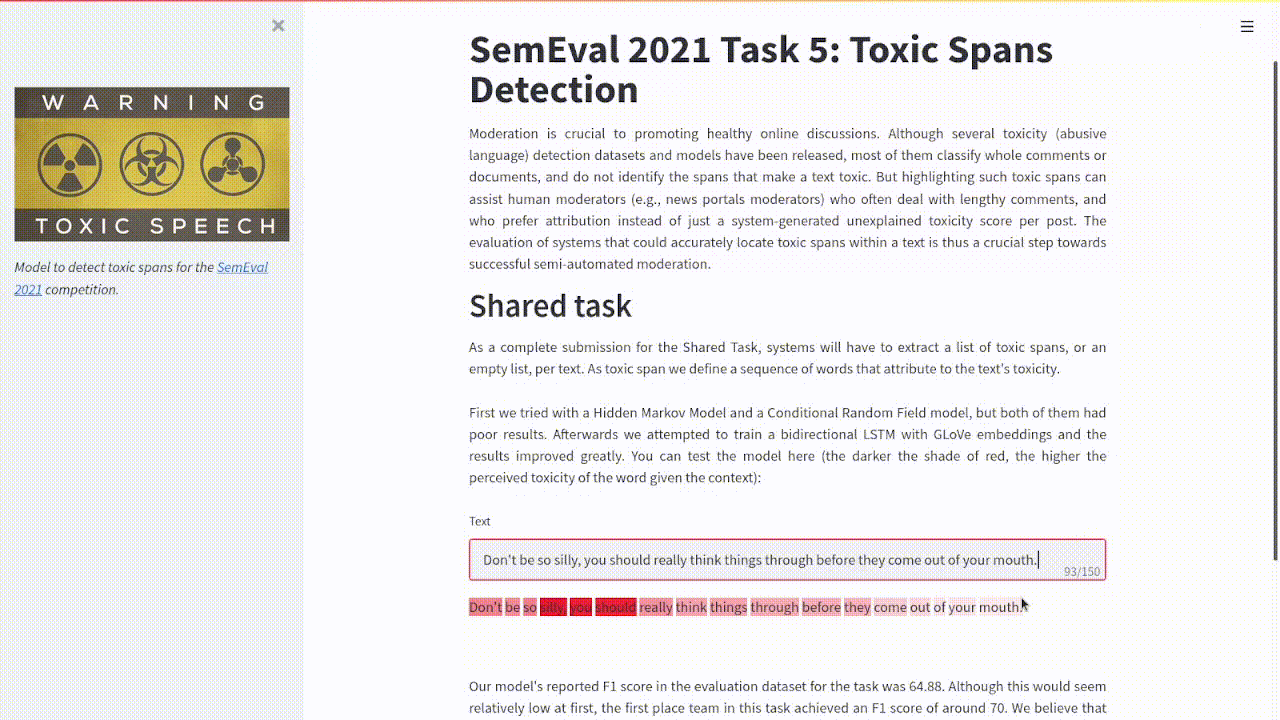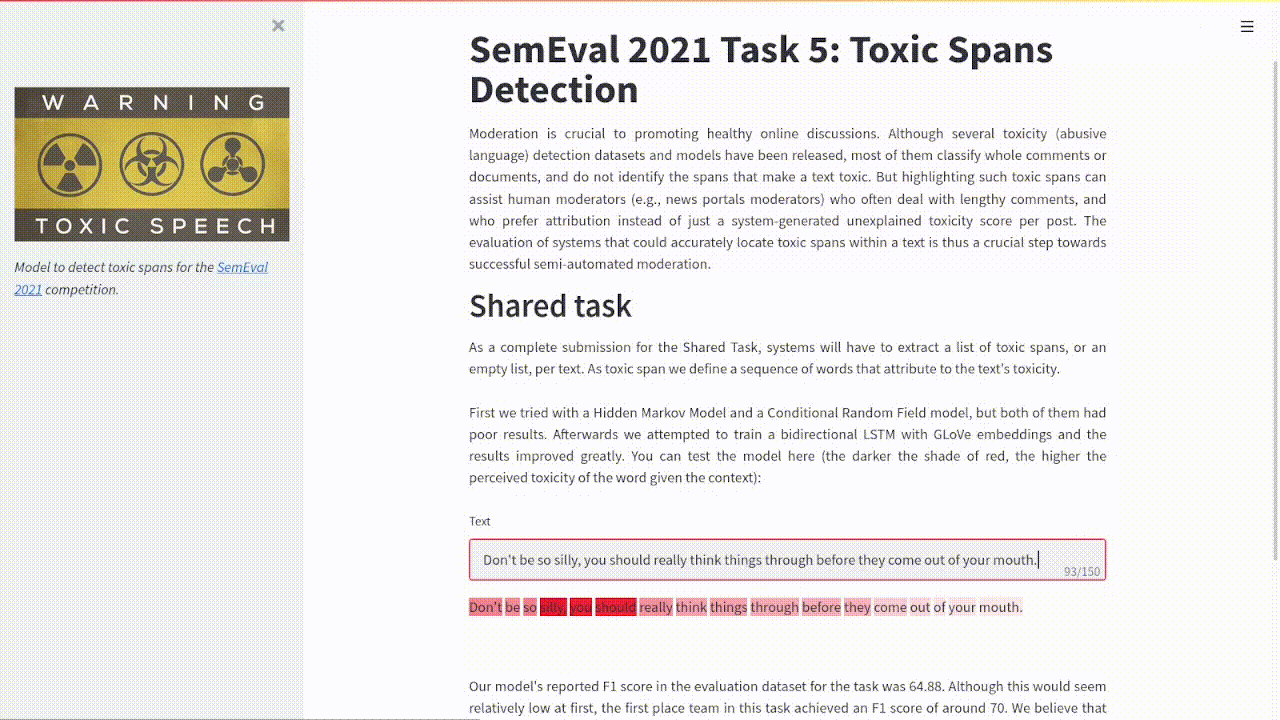
Example of the project's output.
I collaborated with davidguzmanr and roher1727 to create a system that can identify toxic spans of text as proposed in the SemEval 2021 Task 5: Toxic Spans Detection. In this case, we identified the toxicity of each word as a probability given its context in the sentence.
We implemented a bidirectional LSTM architecture working on pretrained GLoVe embeddings that gave a result an of 64.88 F1 score in the evaluation dataset . These were very respectable results considering that the best-performing team in this task got an F1 score of around 70.