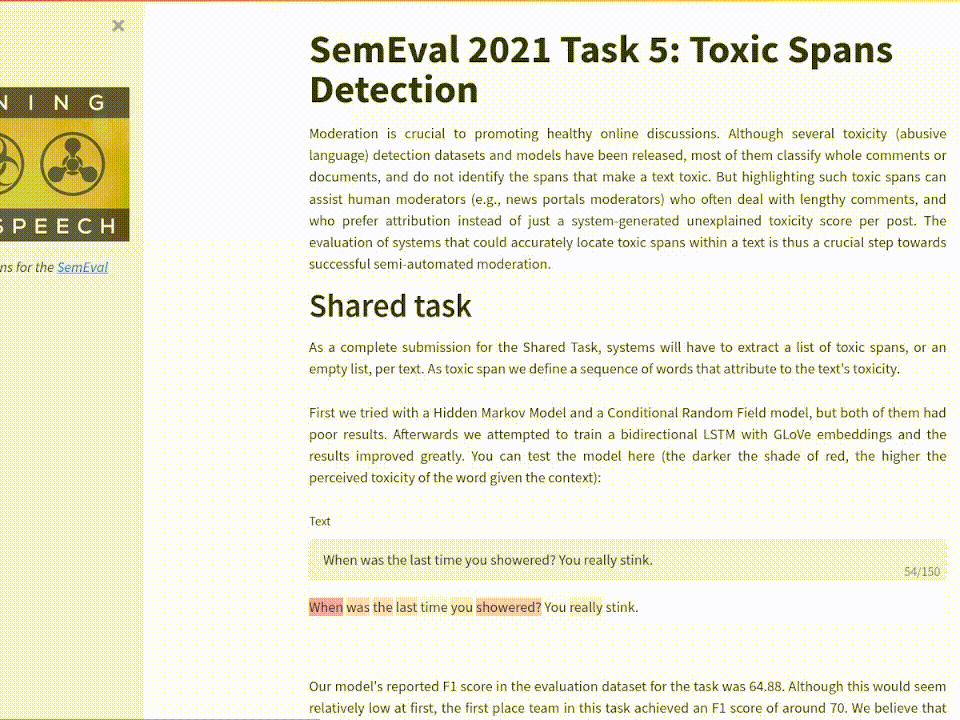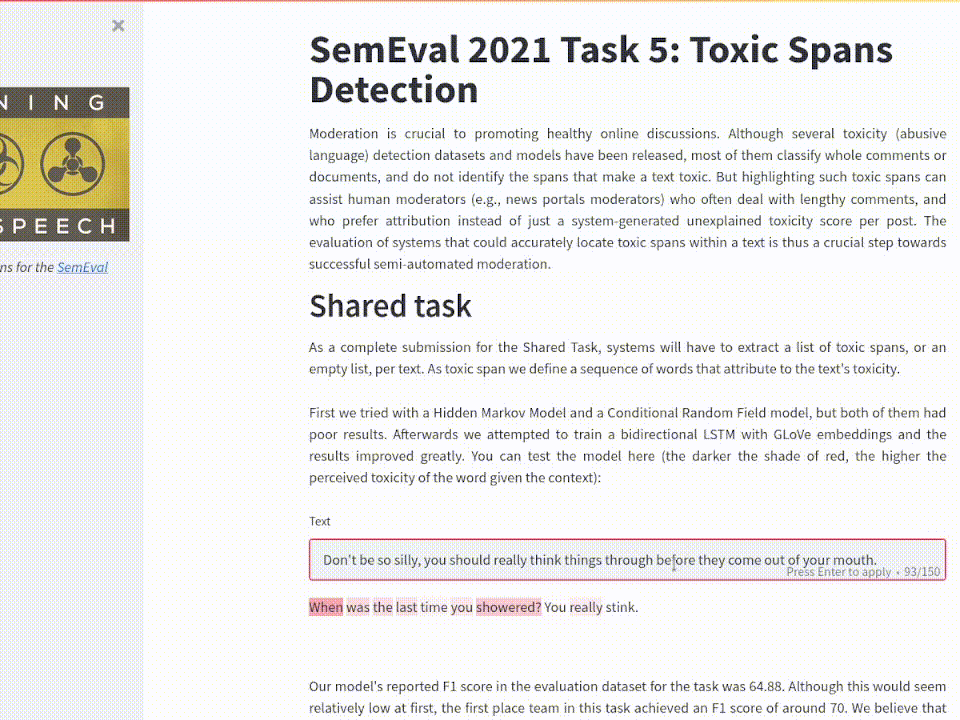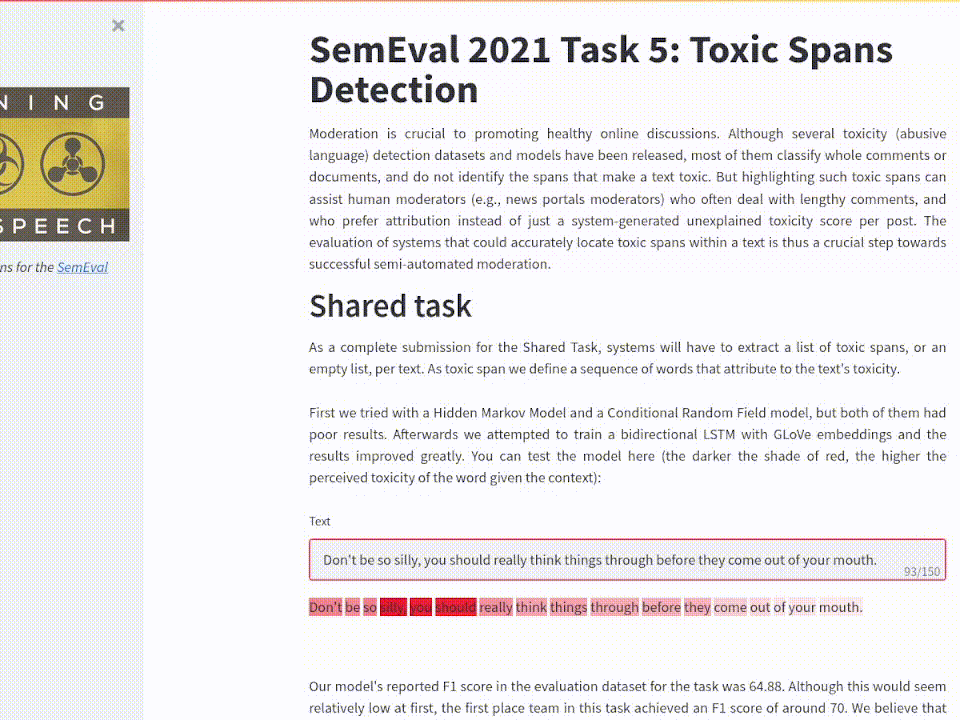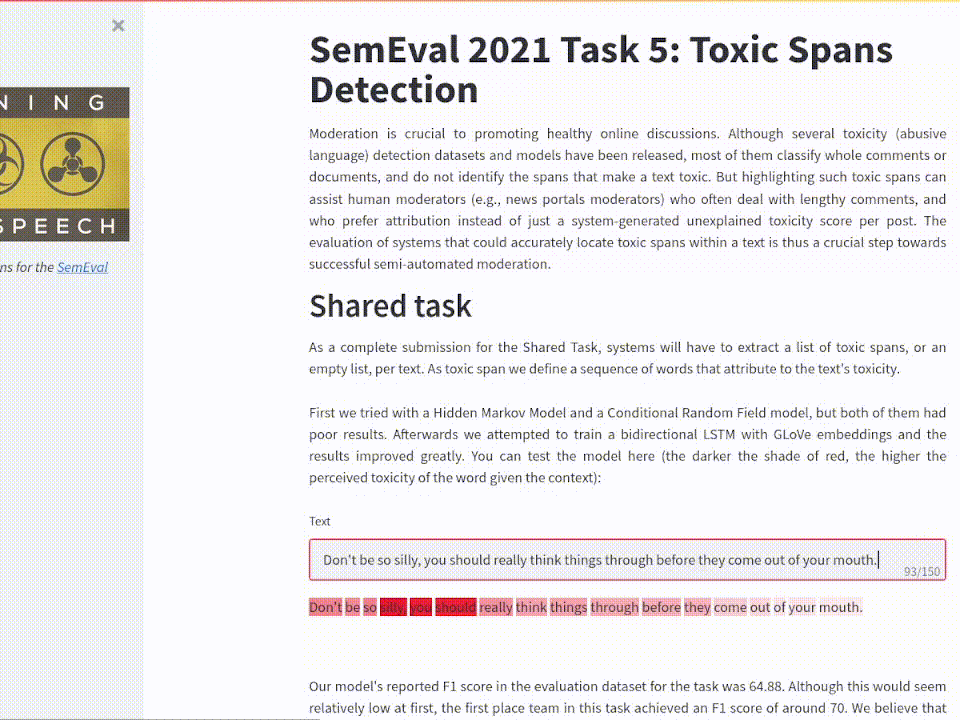
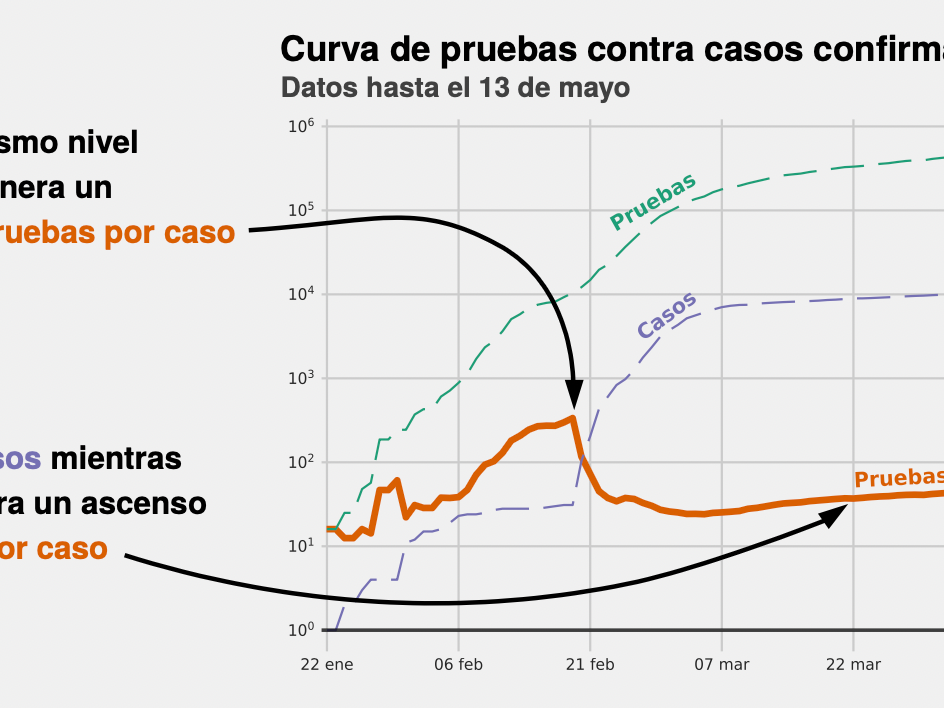
In the digital era, propaganda comes in many different formats. What were overt methods of changing the public's mind in the past have changed into a far more discreet and commonplace form. The SemEval 2021 Task 6: Detection of Persuasion Techniques in Texts and Images presented the problem of identifying the persuasive techniques present in captioned images (memes).

Example propaganda images. The dataset provides the image, its transcription, and the identified persuasion techniques it uses.
The task had different subtasks, of which I chose the third one:
"Given a meme, identify which of the 22 techniques are used both in the textual and visual content of the meme (multimodal task). This is a multilabel classification problem."
For this multimodal learning task, I generated an architecture as described by the following diagram:
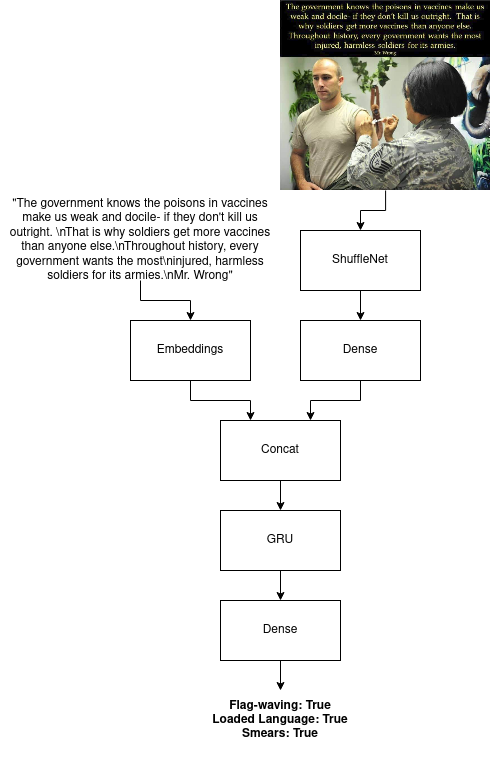
Model used for this task. A pretrained ShuffleNet is fine tuned and then used to extract context information from the image. The context vector is concatenated to a GLoVe embedding for each token analyzed before passing through a GRU.
22 binary outputs are predicted, each of which corresponds to a persuasion technique.
This model achieved a micro-F1 score of 0.4933, which is well above the baseline of solutions for this task. By integrating multiple modalities of data, I was able to predict with far better accuracy than by simply using a recurrent model on the text contained in the images.